Power BI Desktop is an excellent tool for ETL (extract, transform and load) operations and can perform almost any transformation that its big brother, SSIS (SQL Server Integration Services) can.
Most ETL operations can be performed with no code – this is a big plus for those new to Power BI or for rapid report development. Advanced ETL operations are available using DAX and R languages.
In this blog post I will show how Power BI Desktop can be used for data validation prior to use. I am using an open address data-set that has been intentionally modified to include various errors that we will identify and correct throughout the blog post. In the absence of an accompanying data dictionary I will use consistency as a measure of data quality. For example, if 90% of street types are “Street” and 10% are “St.”, “Street” wins.
The process of data validation is iterative… assess, clean, repeat.
Assess RegionDisplayName
- Add a “Table” visualization with RegionDisplayName selected; add a second RegionDisplayName value and format as “Count”; change “Count of RegionDisplayName” to “Show value as” “Percent of grand total”
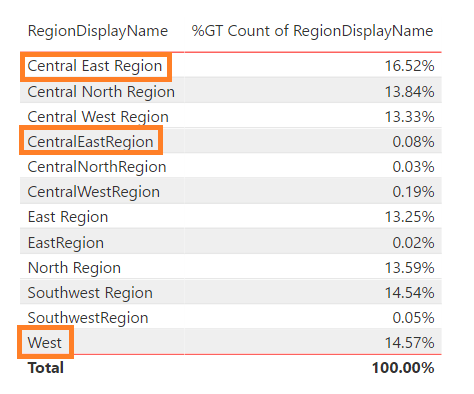
- There are two issues with the RegionDisplayName data. Spacing issues (see “Central East Region” and “CentralEastRegion”) and inconsistent naming standard (see “West”).
Clean RegionDisplayName
- From the Power BI Desktop, click “Edit Queries”
- From the “Query Editor”; click “Transform”; click “Replace Values”

- Enter “CentralEastRegion” for Value to Find; enter “Central East Region” for Replace With
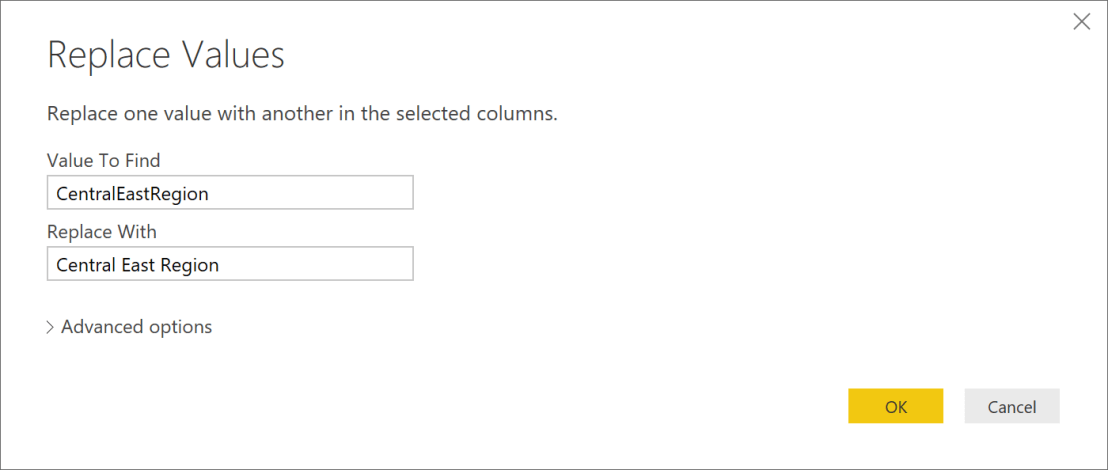
- Click “OK”
- Repeat the above two steps for: “CentralNorthRegion”; “CentralWestRegion”; “EastRegion” and “SouthWestRegion”
- Replace “West” with “West Region”; ensure that Match entire cell contents is checked off

- Click “Close and Apply”
The RegionDisplayName “Table” visualization will now have a more normalized distribution of values.
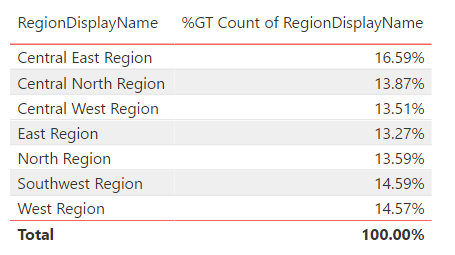
Assess StreetNumber
With address data street numbers aren’t always numbers and invalid characters aren’t always invalid. To assess StreetNumber we will test if values can be converted to numeric and use judgement to assess the outliers and clean as required.
- Click “New Column”
- Enter the following formula: “StreetNumberValid = NOT(ISERROR(‘Address'[StreetNumber] + 0))”

- Add “Table” visualization with StreetNumberValid selected; add a second StreetNumberValid value and format as “Count”; change “Count of StreetNumberValid” to “Show value as” “Percent of grand total”
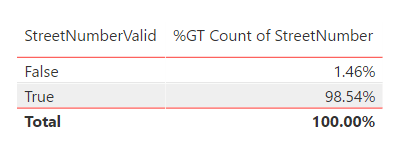
- Add StreetNumber the “Table” visualization; set the Visual level filter to “False” for the “StreetNumberValid” column to see the outliers in the data
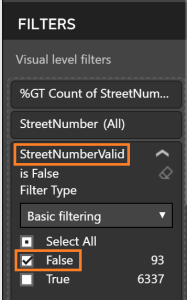
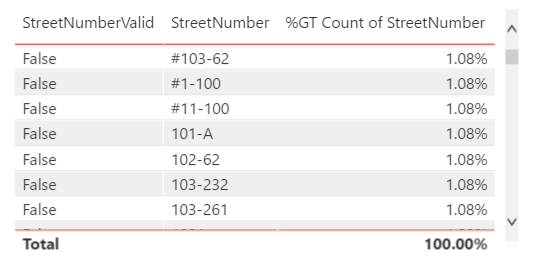
Use the “Replace Values” steps outlined in the RegionDisplayName section above to clean the data as required.
I’ve skipped over StreetType (i.e. Crescent vs Croissant), City (i.e. Barry’s Bay vs Barrys Bay) and Province (i.e. NULL) because they use the same assess and clean approach outlined in RegionDisplayName.
Assess PostalCode
Canadian postal codes are tricky because they follow an alpha numeric pattern of “A1A 1A1”. Regular expressions are not currently supported in Power BI so we have to kluge together an assessment method. I will use two checks in my approach:
- Check for middle space
- Check for the alpha numeric pattern of “A1A 1A1”
Check middle space
- Click “New Column”
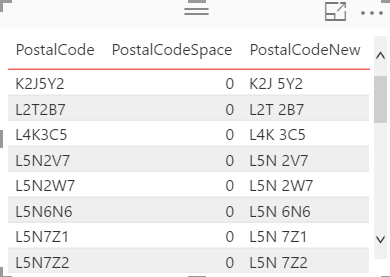
- Enter the following formula: PostalCodeSpace = FIND(” “, ‘Address'[PostalCode], 1, 0)
 Any result with a 0 is missing the space.
Any result with a 0 is missing the space. - Add “Table” visualization with PostalCode selected; add PostalCodeSpace; set the Visual level filter to “0” for the “PostalCodeSpace” column to see the PostalCodes without spaces
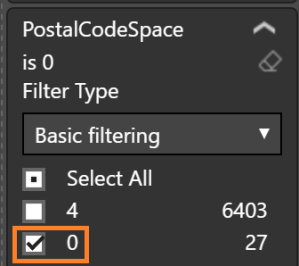
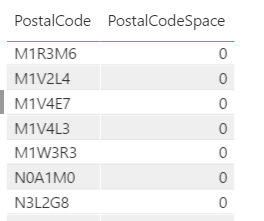
Fix Middle Space
- Click “New Column”
- Enter the following formula: PostalCodeNew = IF(LEN(‘Address'[PostalCode]) <> 7, LEFT(‘Address'[PostalCode], 3) & ” ” & RIGHT(‘Address'[PostalCode], 3), ‘Address'[PostalCode])
- Add PostalCodeNew to the existing PostalCode visual
Check alpha numeric pattern:
- From the Power BI Desktop, click “Edit Queries”
- From the “Query Editor”; click “Transform”; click “Run R Script”
 Important: If you have never executed R scripts in Power BI please see this guide: https://docs.microsoft.com/en-us/power-bi/desktop-r-scripts
Important: If you have never executed R scripts in Power BI please see this guide: https://docs.microsoft.com/en-us/power-bi/desktop-r-scripts
- Enter the following R commands:
output <- dataset
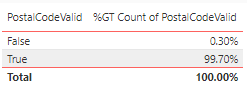
output$PostalCodeValid <- grepl(“^[ABCEGHJ-NPRSTVXY]{1}[0-9]{1}[ABCEGHJ-NPRSTV-Z]{1}[ ]?[0-9]{1}[ABCEGHJ-NPRSTV-Z]{1}[0-9]{1}$”, dataset$PostalCode)
These commands run a regex pattern against PostalCodeNew looking for “A1A 1A1”. Any value not meeting that condition will result in a “False” value. - Click “Close and Apply”
- Add “Table” visualization with PostalCodeValid selected; add a second PostalCodeValid value and format as “Count”; change “Count of PostalCodeValid” to “Show value as” “Percent of grand total”
Power BI Desktop is an excellent tool for data validation. Using a no code approach to ETL will benefit those new to Power BI and those performing rapid report development. Power BI still has a place for advanced ETL using the DAX and R languages.
Thanks for stopping by.
NY
